| Lesson 7 | Rebuilding an index |
| Objective | Modify the way an index is stored. |
Rebuilding Oracle Index
Although an index is an optimized way to access data, the index itself can become inefficient as values are added and deleted to the index. As users change the contents, the index can become fragmented, with holes existing where values were deleted.
When there is a lot of wasted space in the index, Oracle will incur added I/O costs as it retrieves index nodes and leaf blocks that contain wasted space. You may end up with an extra level of index nodes, which means that every index access will take an extra I/O in order to get to the leaf blocks. You also may end up with more leaf blocks than necessary, which would require additional I/O in some situations.
Cleaning up empty space The main way to remove empty space in an index is to rebuild it. You rebuild an index with the
The
An index can also become unbalanced, because the values being added to the index are greater than the previous values in the index. You can address this situation with a reverse key index.
When there is a lot of wasted space in the index, Oracle will incur added I/O costs as it retrieves index nodes and leaf blocks that contain wasted space. You may end up with an extra level of index nodes, which means that every index access will take an extra I/O in order to get to the leaf blocks. You also may end up with more leaf blocks than necessary, which would require additional I/O in some situations.
Cleaning up empty space The main way to remove empty space in an index is to rebuild it. You rebuild an index with the
ALTER INDEX command:
ALTER INDEX bid_auction_idx REBUILD;
The
REBUILD command will completely rebuild the index, filling each of the index nodes and leaf blocks optimally.
Your index should work most efficiently after a REBUILD. You can also coalesce an index, using the keyword COALESCE with the ALTER INDEX command. Coalescing an index only operates on the leaf blocks in the index, by compressing all the empty space and storing it in its own leaf blocks. If you had four leaf blocks that were 50% full, a COALESCE would give you two leaf blocks that were 100% empty.
An index can also become unbalanced, because the values being added to the index are greater than the previous values in the index. You can address this situation with a reverse key index.
Reverse Key Indexes
It is very common to have an index based on a value that is constantly changing.
For instance, if you use a unique ID for each row the ID number will continually get higher. This results in always adding an index value to one side of the index.
As values are deleted from the index, they are deleted from the other side of the index, as these values are older and less useful. The net effect of these two operations is an unbalanced B*-tree structure, where one side of the index has much more empty space than the other.
You can prevent this imbalance with a reverse key index. As the name implies, a reverse key index stores the index values in reverse order. This causes them to be more evenly distributed through the index structure. As an example, the increasing ID values of 234, 235 and 236 will be stored as 432, 532 and 632, which will be distributed throughout the leaf blocks of the index. Oracle will automatically translate reverse key values on storing and retrieving them.
Of course, you cannot use a reverse key index for sorting.
As values are deleted from the index, they are deleted from the other side of the index, as these values are older and less useful. The net effect of these two operations is an unbalanced B*-tree structure, where one side of the index has much more empty space than the other.
You can prevent this imbalance with a reverse key index. As the name implies, a reverse key index stores the index values in reverse order. This causes them to be more evenly distributed through the index structure. As an example, the increasing ID values of 234, 235 and 236 will be stored as 432, 532 and 632, which will be distributed throughout the leaf blocks of the index. Oracle will automatically translate reverse key values on storing and retrieving them.
Of course, you cannot use a reverse key index for sorting.
Oracle Database 12c
Reverse Key Index
A reverse key index is a type of B-tree index that physically reverses the bytes of each index key while keeping the column order.
For example, if the index key is 20, and if the two bytes stored for this key in hexadecimal are C1,15 in a standard B-tree index, then a reverse key index stores the bytes as 15,C1.
Reversing the key solves the problem of contention for leaf blocks in the right side of a B-tree index. This problem can be especially acute in an Oracle Real Application Clusters (Oracle RAC) database in which multiple instances repeatedly modify the same block. For example, in an orders table the primary keys for orders are sequential. One instance in the cluster adds order 20, while another adds 21, with each instance writing its key to the same leaf block on the right-hand side of the index. In a reverse key index, the reversal of the byte order distributes inserts across all leaf keys in the index. For example, keys such as 20 and 21 that would have been adjacent in a standard key index are now stored far apart in separate blocks. Thus, I/O for insertions of sequential keys is more evenly distributed. Because the data in the index is not sorted by column key when it is stored, the reverse key arrangement eliminates the ability to run an index range scanning query in some cases. For example, if a user issues a query for order IDs greater than 20, then the database cannot start with the block containing this ID and proceed horizontally through the leaf blocks.
Reversing the key solves the problem of contention for leaf blocks in the right side of a B-tree index. This problem can be especially acute in an Oracle Real Application Clusters (Oracle RAC) database in which multiple instances repeatedly modify the same block. For example, in an orders table the primary keys for orders are sequential. One instance in the cluster adds order 20, while another adds 21, with each instance writing its key to the same leaf block on the right-hand side of the index. In a reverse key index, the reversal of the byte order distributes inserts across all leaf keys in the index. For example, keys such as 20 and 21 that would have been adjacent in a standard key index are now stored far apart in separate blocks. Thus, I/O for insertions of sequential keys is more evenly distributed. Because the data in the index is not sorted by column key when it is stored, the reverse key arrangement eliminates the ability to run an index range scanning query in some cases. For example, if a user issues a query for order IDs greater than 20, then the database cannot start with the block containing this ID and proceed horizontally through the leaf blocks.
Reuse of Index Space
The database can reuse space within an index block. For example, if you insert a value into a column and delete it, and if an index exists on this column, then the database can reuse the index slot when a row requires it.
The database can reuse an index block itself. Unlike a table block, an index block only becomes free when it is empty. The database places the empty block on the free list of the index structure and makes it eligible for reuse.
However, Oracle Database does not automatically compact the index: an ALTER INDEX REBUILD or COALESCE statement is required.
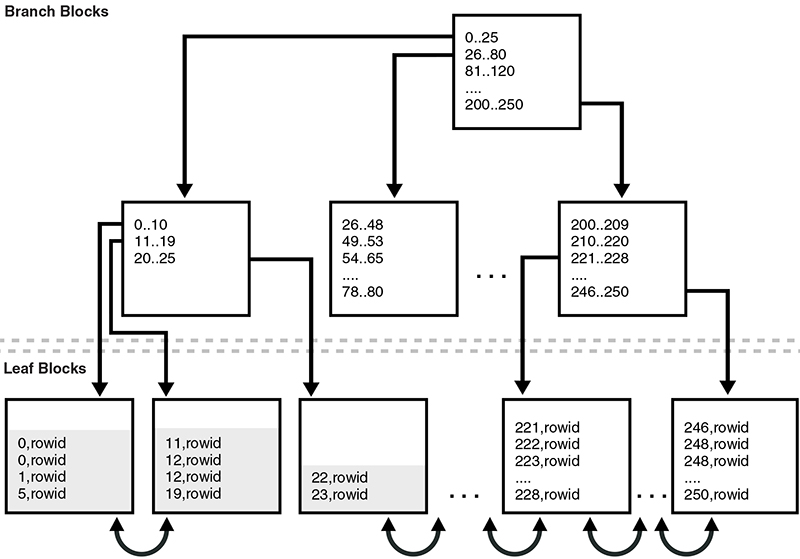
Figure 5-1 represents an index of the employees.department_id column before the index is coalesced. The first three leaf blocks are only partially full, as indicated by the gray fill lines.
Figure 5-1 represents an index of the employees.department_id column before the index is coalesced. The first three leaf blocks are only partially full, as indicated by the gray fill lines.
Branch Blocks
|
Leaf Blocks
|
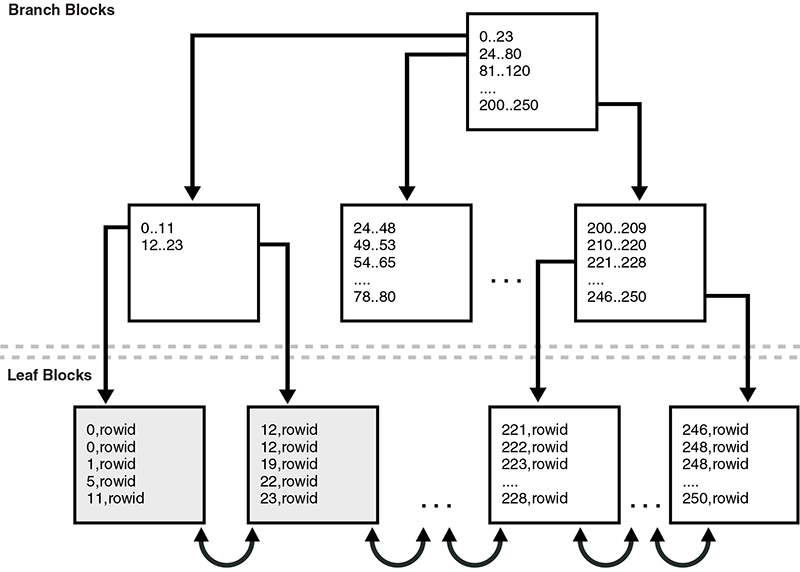
Figure 5-2 shows the index in Figure 5-1 after the index has been coalesced. The first two leaf blocks are now full, as indicated by the gray fill lines, and the third leaf block has been freed.
Altering Indexes - Quiz
Click the Quiz link below to answer a few questions about altering indexes.
Altering Indexes - Quiz
The next lesson shows how to get information about indexes from the data dictionary.
Altering Indexes - Quiz
The next lesson shows how to get information about indexes from the data dictionary.