You can add an index to any existing table. You use the same basic syntax to create an index as to create other database objects using Data Definition Language.
Syntax: The basic syntax for creating an index consists of these clauses:
CREATE:
The CREATE keyword is required as the beginning of this SQL statement.
UNIQUE/BITMAPPED:
You can use either of these keywords to make the index either unique or use a bitmapped structure. If you do not specify either, you will create an index that allows duplicate values. You can only use one of these keywords, so you cannot specify a unique, bitmapped index.
INDEX:
The INDEX keyword is required as part of this DDL table.
index_name:
The index_name must be unique for indexes in a particular schema. You also can specify a schema name as a prefix to the index name if you are creating indexes in a schema other than the one belonging to your current username.
ON table name:
The ON keyword is required, and the table_name may have to be qualified with a schema name.
( col_name1, col_name2, ...):
You can specify up to 32 columns in an Oracle index.
ASC/DESC:
These keywords specify that the index should be sorted in ascending (ASC) or descending (DESC) order. The default order is ascending.
If you wanted to add an index for the BIDDER_CLIENT_ID column in the BID table, you would use the following syntax.
CREATE INDEX bid_client_idx
ON bid (bidder_client_id) ASC;
This index will allow duplicate values, because it is not specified as UNIQUE. Although the index will be sorted in ascending order by default, it is always good practice to specify the sort order. If you define a UNIQUE or PRIMARY KEY constraint, Oracle will, by default, create the appropriate index to support the constraint.
Overview of Indexed Clusters
An indexed cluster is a table cluster that uses an index to locate data. The cluster index is a B-tree index on the cluster key. A cluster index must be created before any rows can be inserted into clustered tables. Assume that you create the cluster employees_departments_cluster with the cluster key department_id, as shown in Example 5-4. Because the HASHKEYS clause is not specified, this cluster is an indexed cluster. Afterward, you create an index named idx_emp_dept_cluster on this cluster key.
Example 5-4 Indexed Cluster
CREATE INDEX idx_emp_dept_cluster
ON CLUSTER employees_departments_cluster;
You then create the employees and departments tables in the cluster, specifying the department_id column as the cluster key, as follows (the ellipses mark the place where the column specification goes):
Finally, you add rows to the employees and departments tables. The database physically stores all rows for each department from the employees and departments tables in the same data blocks. The database stores the rows in a heap and locates them with the index.
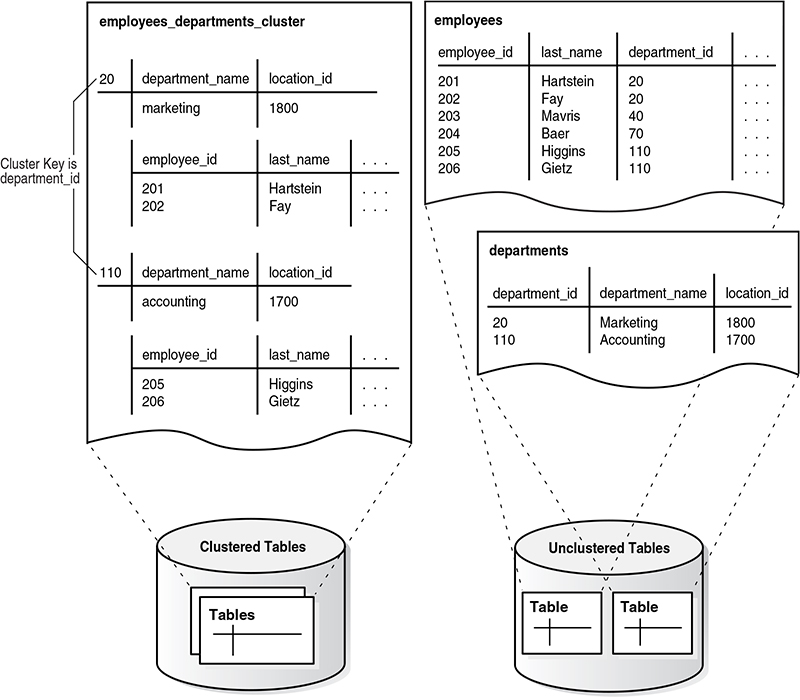
Figure 5-6 shows the employees_departments_cluster table cluster, which contains employees and departments. The database stores rows for employees in department 20 together, department 110 together. If the tables are not clustered, then the database does not ensure that the related rows are stored together.
Figure 5-6: Clustered Table Data
Text Transcription:
employees_departments_cluster
Cluster Key is department_id
20
department_name: marketing
location_id: 1800
employee_id: 201, last_name: Hartstein
employee_id: 202, last_name: Fay
110
department_name: accounting
location_id: 1700
employee_id: 205, last_name: Higgins
employee_id: 206, last_name: Gietz
employees
employee_id, last_name, department_id, ...
201, Hartstein, 20
202, Fay, 20
203, Mavris, 40
204, Baer, 70
205, Higgins, 110
206, Gietz, 110
departments
department_id, department_name, location_id
20, Marketing, 1800
110, Accounting, 1700
Clustered Tables
Icon representing clustered tables with the label "Tables"
Unclustered Tables
Icon representing unclustered tables with the label "Table"
Relevant Features:
Clustered Tables: The main feature on the left side of the image is a clustered table representation, where data from multiple tables (e.g., employees and departments) is grouped by a common key, department_id. The cluster is labeled employees_departments_cluster, and the "Cluster Key" is defined as department_id. This means that records are physically stored together based on this key, reducing the need for joins and improving query performance for queries based on department_id.
Unclustered Tables: On the right side of the image, there are two separate unclustered tables, employees and departments, each with its data stored independently. In unclustered tables, the data is stored without grouping by a common key, so joining tables would require additional processing to match rows based on keys like department_id.
Diagram Structure: The image is structured to contrast clustered tables with unclustered tables. The arrows demonstrate how department_id connects entries in the employees and departments tables within the clustered structure, while the unclustered tables do not have this optimized grouping.
The next lesson explores storage considerations for index structures.