Once the database link has been created, you can reference it in the SQL. There are two types of transactions you can accomplish via database links: (1) a simple distributed query, and (2) a distributed update.
Still True in Oracle 23c:
Oracle 23c continues to support database links (`DBLINK`) that allow a local database to access objects in a remote database via SQL statements.
Simple distributed queries (SELECT * FROM remote_table@remote_db) still work.
Distributed updates (INSERT, UPDATE, DELETE on remote objects) are still supported through two-phase commit (2PC) mechanisms.
🧠 Enhancements in Oracle 23c
Here’s what’s *new or improved* in Oracle 23c, especially in cloud/network topologies:
Auto CDB-to-CDB links
You can now more easily link PDBs across CDBs, even in multi-tenant cloud configurations.
Secure communication
Oracle 23c encourages TLS-encrypted communication and supports wallet-based authentication for DB Links in cloud environments.
Globally Distributed Transactions
You can use Application Continuity and Transaction Guard in conjunction with distributed transactions for fault resilience.
Cross-Region Support in Oracle Cloud
With the right TNS configuration and security policies, you can have cross-region DB links in OCI, supporting distributed queries and updates across Oracle Cloud regions.
Oracle Cloud Autonomous Database (limited)
If using Oracle Autonomous DBs, note that CREATE DATABASE LINK is not always available—instead, Oracle recommends using REST-based APIs or Oracle GoldenGate for such use cases.
🛠️ Example (Still Works in 23c):
SELECT * FROM employees@hrdb_link;
UPDATE employees@hrdb_link
SET salary = salary * 1.1
WHERE department_id = 10;
🔒 Best Practice for Oracle 23c Cloud:
Use CREATE DATABASE LINK ... IDENTIFIED BY VALUES with wallet-based credentials.
Ensure Oracle Net configuration (tnsnames.ora / Easy Connect) is correct in multi-CDB setups.
Monitor and log distributed transaction behavior using DBA_2PC_PENDING, V$GLOBAL_TRANSACTION, and Oracle's new event-driven diagnostics.
The following sentence still hold true for "Oracle network topology" in their cloud platform Oracle 23c.
Once the database link has been created, you can reference it in the SQL.
There are two types of transactions you can accomplish via database links:
SELECT order_number, item_number
FROM
order@raleigh o,
Item@rochester i
WHERE
o.item_number = i.item_number;
Distributed Update
A distributed update modifies data on two or more nodes. A distributed update is possible using a PL/SQL subprogram unit, such as a procedure or trigger, that includes two or more remote updates accessing data on different nodes.
In the example below, I have decremented the inventory at the Rochester plant before adding the order to the database at Raleigh.
BEGIN
UPDATE item@rochester
SET quantity_on_hand = quantity_on_hand - 1
WHERE item_id = 12345;
INSERT INTO order@raleigh
VALUES (‘order_number’,’item_number);
END;
The two-phase commit
This ensures that the inventory adjustment and the order entry happen as a single transaction. The RECO Oracle process on the remote nodes is used to ensure that both nodes complete their piece of the transaction before the whole distributed transaction is committed to each database. This is known as a two-phase commit. As the name implies, the two-phase commit works in two distinct steps.
The first step is the prepare phase, where the rows are prepared to be committed to the remote databases.
The second phase, called the commit phase, is where the entire distributed transaction is either committed or rolled back as a single unit of work. The following figure illustrates the process.
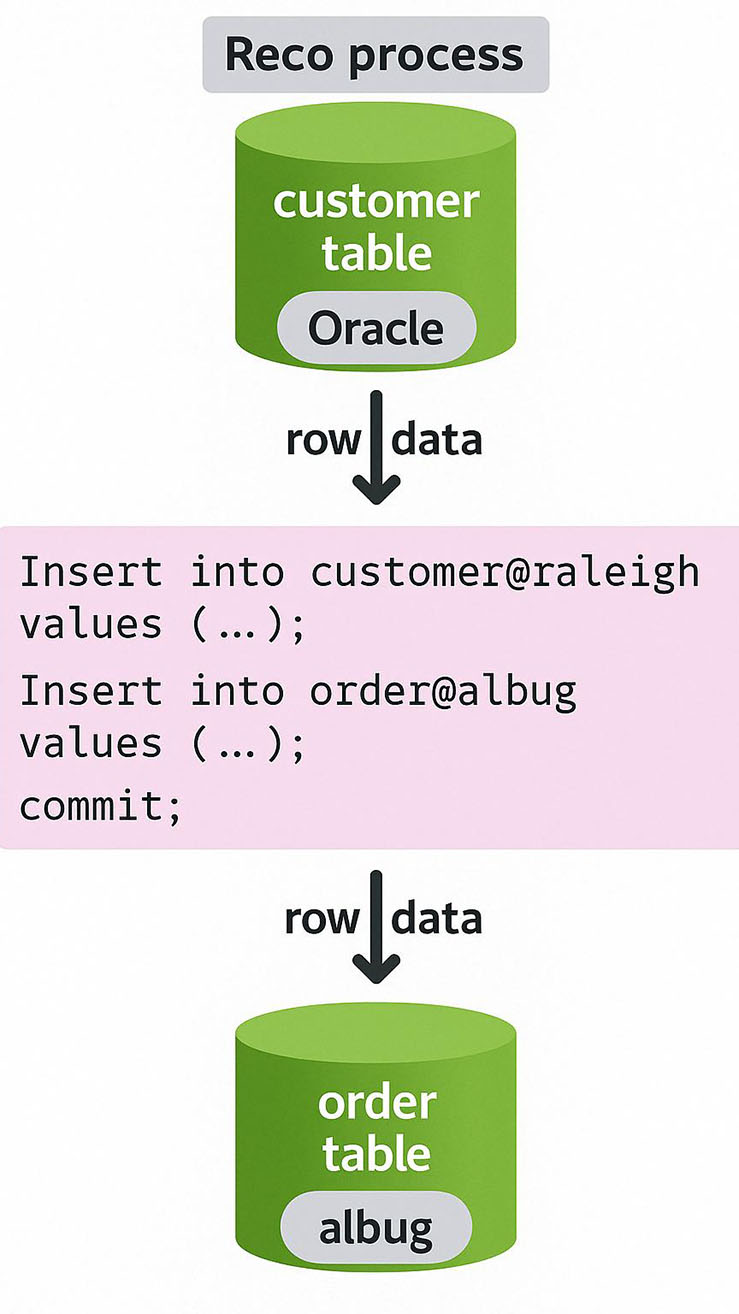
This image illustrates a distributed transaction using Oracle Database Links (DB Links) within an Oracle network topology.
Here's a breakdown of its components and corresponding SQL:
🔧 Network Topology Components
Reco process (Top - Raleigh Site)
Represents an Oracle recovery (RECO) process at the Raleigh site.
This process is responsible for resolving in-doubt distributed transactions.
Connected to a customer table.
SQL Statement Area (Middle)
Shows the actual SQL commands being executed, utilizing Oracle DB Links:
Insert into customer@raleigh values (...);
Insert into order@albug values (...);
commit;
These statements initiate inserts across two physically separate Oracle databases (via @raleigh and @albug).
Reco process (Bottom - Albug Site)
Another Oracle RECO process at the Albug site.
Connected to an order table.
Handles recovery responsibilities if the distributed transaction fails or hangs.
Direction of Data Flow
Arrows labeled "row data" indicate the flow of data to the respective remote databases via network communication.
📜 Explanation of SQL Commands
These SQL statements perform a coordinated distributed transaction:
Insert into customer@raleigh values (...);
Insert into order@albug values (...);
commit;
customer@raleigh references a remote customer table using a database link named raleigh.
order@albug references a remote order table via the albug DB link.
The COMMIT ensures two-phase commit (2PC) is used to maintain transactional integrity across both remote sites.
🔄 Oracle Two-Phase Commit (2PC) Role
Oracle uses the RECO process to:
Automatically resolve in-doubt transactions that may occur if a network failure or crash happens during commit.
Ensure atomicity across distributed environments.
🧠 Summary
This diagram models a distributed update across two Oracle databases (raleigh and albug) using database links.
SQL spans both databases and is finalized with a two-phase commit.
RECO processes at each site handle recovery if transaction coordination fails.
Insert into customer@raleigh values ();
Insert into order@albug values ();
commit;
Remember, location transparency is easily achieved by hiding the service name with a public synonym.
For example, if you do not want your
programmers to be concerned that your inventory database is in Rochester, you could create the following synonym:
CREATE PUBLIC SYNONYM item for item@rochester
Now all SQL references to the ITEM table will transparently reference item@rochester. The next lesson concludes this module.
[1]Distributed query: Within an Oracle Network Topology, a distributed query is a single SQL statement that accesses data from multiple distinct Oracle databases across the network. This allows users to retrieve and combine information residing in different database instances as if they were a single, unified data source.