Explain the Evolution from Centralized to Decentralized Computers.
Evolution from Centralized to Decentralized Computers
While the computing environment of the 1990s is characterized by widely distributed systems, this decentralized database approach is actually a relatively new phenomenon. It is very important to understand that the client/server model does much more than distribute data across a network. One of the foremost reasons for using the client/server model is to share the processing load.
Central data, central processing, distributed data, distributed processing
In the four quadrants of this graph, we see several common approaches to the distribution of Oracle data and processors:
Centralized Data, Centralized processing (no networking)
This is the traditional approach to Oracle data, where all the data resides in a common database and all the processing is performed by a centralized computer, usually a large UNIX server. This approach has the advantage of better control of the Oracle data, but has the disadvantage of being subject to widespread performance degradation when the CPU becomes overloaded. Because there is also a single point of failure , which is CPU of the Unix machine, the probability of experiencing downtime is increased. If this single CPU would fail, this problem could cripple the entire system, making access to the data impossible.
For this reason it is better to focus on a solution that involves distributed networks. A distributed network would enable the data as well as the CPU to be de-centralized, thus preventing the possibility of hardware or database failure.
Centralized Database: A centralized database (sometimes abbreviated CDB) is a database that is located, stored, and maintained in a single location.
This location is most often a central computer or database system, for example a desktop or server CPU, or a mainframe computer. In most cases, a centralised database would be used by an organisation (for example a business company) or an institution. Users access a centralised database through a computer network which is able to give them access to the central CPU, which in turn maintains to the database itself. All of the information stored on the CBS is accessible from a large number of different points, which in turn creates a significant amount of both advantages and disadvantages.
Technologies which replaced the Oracle Parallel Server
Oracle did not replace Oracle Parallel Server (OPS) with a single technology. Instead, OPS evolved into Real Application Clusters (RAC). RAC builds upon the core concepts of OPS, such as shared disk architecture and instance coordination, while introducing enhanced features like:
Cache Fusion: Improves scalability and performance by allowing instances to share data blocks directly in memory, reducing the need for disk I/O.
Enhanced Cluster Interconnect: Utilizes faster and more reliable interconnect technologies for improved communication between nodes.
Greater Flexibility: Supports a wider range of configurations, including different operating systems and hardware platforms.
While RAC is the spiritual successor to OPS, Oracle also introduced other technologies that complement RAC's capabilities:
In-Memory Parallel Execution (IMPX): Leverages shared memory (SGA) to store data for subsequent parallel processing, improving performance for large-scale environments.
Grid Infrastructure: Provides a unified infrastructure for managing multiple databases and clusters, simplifying administration and maintenance.
Overall, RAC, in combination with other advancements, represents the evolution of Oracle's approach to high availability and scalability, building upon the foundation laid by OPS.
Oracle parallel server(OPS) was a technology that allowed two or more database instances, generally on different machines, to open and manipulate one database. In other words, the physical data files (and therefore data) in a database could be seen, inserted, updated, and deleted by users logging on to two or more different instances. These instances run on different machines but access the same physical database. Oracle Parallel Server required an operating system that supported clustering and a distributed lock manager because the multiple database instances had to share information about the data that was updated.
For example, if a user on instance A updated a row, and a user on instance B performed a query that would return that row, instance B would instruct instance A to write the updated data to the physical database so that the query would deliver the updated information. Oracle Parallel Server is intended to provide failover capabilities, which allow a second machine to take over the processing being performed by the first in the event of machine failure (e.g., CPU or motherboard failure). It does not provide any protection from disk failure. Occasionally, parallel server technology is used to achieve horizontal scalability.
Centralized Data and Distributed Processing
This is a configuration in which the data resides in a central, controlled environment, but the processing is distributed across a network of remote CPUs.
The main advantage to this approach is the control over the data and the ability to have redundant CPUs for extra reliability and scalability.
The main disadvantage is that the Oracle database becomes a single point of failure, and a runaway Oracle task could slow down the entire system. Oracle implements this approach with its Oracle Parallel Server (OPS) product. A parallel database system seeks to improve performance through parallelization of various operations, such as loading data, building indexes and evaluating queries. Although data may be stored in a distributed fashion, the distribution is governed solely by performance considerations. Parallel database improves processing and input/output speeds by using multiple
CPUs and disks in parallel. Centralized and client-server database systems are not powerful enough to handle such applications.
In parallel processing, many operations are performed simultaneously, as opposed to serial processing, in which the computational steps are performed sequentially.
Distributed Data, Centralized processing
This is a common approach for geographically distributed Oracle systems. A centralized processor does all the work, while remote data hubs access the data. The computers at the remote nodes act only as data servers, with all the processing being done by a large central processor. The main advantage to this approach is the proximity of the data to the user in a distributed network, and the main disadvantage is the lack of centralized control over backup and recovery of the data.
This is the standard configuration for Oracle Network Services.
Distributed Database System:
A distributed database system consists of loosely coupled sites that share no physical component.
Database systems that run on each site are independent of each other
Transactions may access data at one or more sites
Homogeneous Distributed Databases:
In a homogeneous distributed database
All sites have identical software
Are aware of each other and agree to cooperate in processing user requests.
Each site surrenders part of its autonomy in terms of right to change schemas or software
Appears to user as a single system
Heterogeneous Distributed Database:
In a heterogeneous distributed database
Different sites may use different schemas and software 1) Difference in schema is a major problem for query processing, 2) Difference in softwrae is a major problem for transaction processing
Sites may not be aware of each other and may provide only limited facilities for cooperation in transaction processing
History of Distributed Databases
The ability to create a distributed database has existed since the late 1970s.
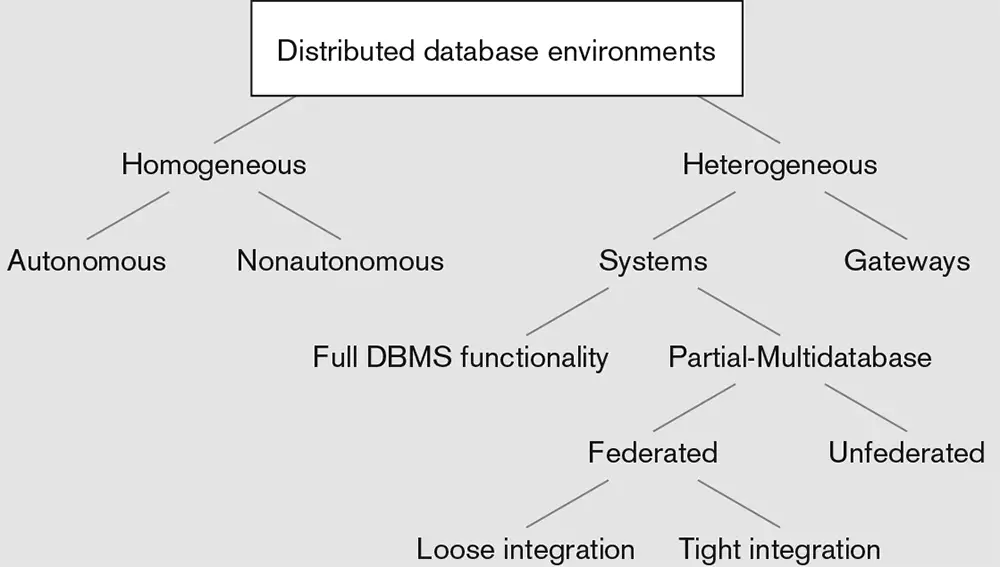
As you might expect, a variety of distributed database options exist. Figure 3-2 outlines the range of distributed database environments. These environments are briefly explained by the following:
Homogeneous: The same DBMS is used at each node.
Autonomous Each DBMS works independently, passing messages back and forth to share data updates.
Nonautonomous A central, or master, DBMS coordinates database access and update across the nodes.
Heterogeneous: Potentially different DBMSs are used at each node.
Systems Supports some or all of the functionality of one logical database.
Full DBMS functionality Supports all of the functionality of a distributed database.
Figure 3-2: Distributed database environments
Managing Distributed Databases
Due to the volatile nature of corporate computing that existed during the 1990's many corporations were faced with the issue of managing widely distributed database systems, spanning geographical areas, hardware platforms and database architectures.
Other shops embraced
downsizing and
rightsizing
and reated situations where many diverse islands of information were spread across many computer networks.
Distributed Data Processing
This is the approach of many Oracle systems, whereby both
the data and
the processing
are distributed across a network is to use a distributed database.
The primary advantage to this approach is the ability to assign both data and processors on an as-needed basis.
The main disadvantage is the problem of coordinating backup and recovery of the data across all the distributed nodes.
This is implemented with Oracle Parallel Server with Oracle Net Services interfaces to remote databases.
Distributed query processing in Oracle can be described as follows. In Oracle, the query is executed at the node that the user is signed-on to,
while other database's partition a distributed query into sub-queries, executing each subquery on it's host processor. In Oracle, a distributed query might query data items from widely distributed databases in a single query.
Oracle implements distributed queries using database links.
Query Performance
The performance of a query should not depend on where the data resides. The optimization of distributed queries is vital because a poor execution plan can take orders of magnitude longer than the "correct" one. For example, if a query includes a large intermediate result set, that data probably should not be shipped over the network to the database with a small table that is to be joined with the result set.
All systems fall somewhere within these four domains, depending on the amount of distributed processing and number of distributed databases.
The Oracle solution facilitates all of them. A distributed data store is a network in which a user stores his or her information on a number of peer network nodes. The user also usually reciprocates and allows users to use his or her computer as a storage node as well. Information may or may not be accessible to other users depending on the design of the network.
Distributed databases have become an integral part of business computing in the last 30 years.
The ability to maintain the integrity of data and provide accurate and timely processing of database queries and updates across multiple sites has been an important factor in enabling businesses to utilize data in a range of different locations, sometimes on a global scale. Standardization of query languages, and of the Relational and Object models has assisted the integration of different database systems to form networks of integrated data services. The difficulties of ensuring the integrity of data, that updates are timely, and that users receive a uniform rate of response no matter where on the network they are situated remain, in many circumstances, major challenges to database vendors and users.
In this unit we shall introduce the topic of distributed database systems. We shall examine a range of approaches to distributing data across networks, and examine a range of strategies for ensuring the integrity and timeliness of the data concerned.
We shall look at mechanisms for enabling transactions to be performed across different machines, and the various update strategies that can be applied when data is distributed across different sites. In the next lesson, we will take a look at the evolution of network protocols.