| Lesson 6 | Hash clusters |
| Objective | Know When to use Oracle Hash Cluster |
When to use Oracle Hash Cluster
There is another type of clustering available in your Oracle database that is called a hash cluster. A hash cluster is similar in most respects to a standard cluster. The data in a hash cluster is grouped according to a value, which is stored in a cluster index.
Oracle Hash Table Clusters
- How is a hash cluster different?
The big difference between a hash cluster and a normal cluster is the way the data is accessed. In a regular cluster, Oracle uses the value of the cluster key to access the data in the cluster. In a hash cluster, Oracle uses the value of a hashing function to access the data in the cluster. The following series of images illustrates a hash cluster in action:
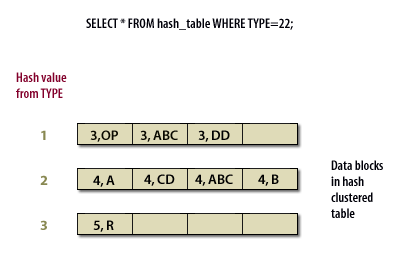
| Hash Value from TYPE | Data Blocks Hash Clustered Table | |----------------------|----------------------------------| | 1 | 3, OP | 3, ABC | 3, DD | | 2 | 4, A | 4, CD | 4, ABC | 4, B | | 3 | 5, R |This table represents how the records are stored in the hash clustered table, with data blocks grouped by their hash values derived from the `TYPE` column.
SELECT * FROM hash_table WHERE TYPE =22;
A user issues a SELECT statement based on the value of the cluster key in the hashed cluster.
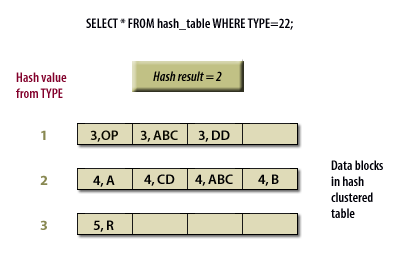
SELECT * FROM hash_table WHERE TYPE =22;
Oracle parses the value with the specified hash cluster.
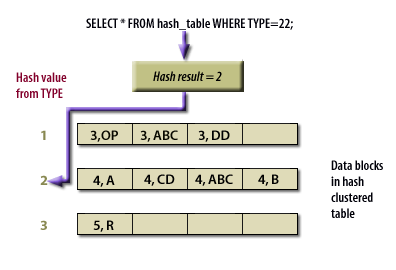
SELECT * FROM hash_table WHERE TYPE =22;Oracle uses the resultant hash value to directly access the appropriate cluster.
Overview of Hash Clusters
A hash cluster is like an indexed cluster, except the index key is replaced with a hash function. No separate cluster index exists. In a hash cluster, the data is the index. With an indexed table or indexed cluster, Oracle Database locates table rows using key values stored in a separate index. To find or store a row in an indexed table or table cluster, the database must perform at least two I/O operations:
A hash cluster is similarly used with cluster tables, the difference being a hash cluster uses a hash function instead of the index key.
- One or more I/Os to find or store the key value in the index
- Another I/O to read or write the row in the table or table cluster
- A table is queried much more often than modified.
- The hash key column is queried frequently with equality conditions, for example, WHERE department_id=20. For such queries, the cluster key value is hashed. The hash key value points directly to the disk area that stores the rows.
- You can reasonably guess the number of hash keys and the size of the data stored with each key value.
- About Hash Clusters
Storing a table in a hash cluster is an optional way to improve the performance of data retrieval. A hash cluster provides an alternative to a non-clustered table with an index or an index cluster. With an indexed table or index cluster, Oracle Database locates the rows in a table using key values that the database stores in a separate index. To use hashing, you create a hash cluster and load tables into it. The database physically stores the rows of a table in a hash cluster and retrieves them according to the results of a hash function. Oracle Database uses a hash function to generate a distribution of numeric values, called hash values, that are based on specific cluster key values. The key of a hash cluster, like the key of an index cluster, can be a single column or composite key (multiple column key). To find or store a row in a hash cluster, the database applies the hash function to the cluster key value of the row. The resulting hash value corresponds to a data block in the cluster, which the database then reads or writes on behalf of the issued statement. To find or store a row in an indexed table or cluster, a minimum of two (there are usually more) I/Os must be performed:- One or more I/Os to find or store the key value in the index
- Another I/O to read or write the row in the table or cluster
Hashing Function
The hashing function is an algorithm that acts on the values in the cluster key. Because of this, all the values in a cluster key for a hash cluster must be numeric. Oracle can either use its standard hashing algorithm, or you can assign a specific hashing function for a hash cluster. A hash cluster differs from a normal cluster in that the hash value is not stored in the cluster itself. In addition, although a cluster index is required for a regular cluster, you cannot create a cluster index on a hash cluster. Because there is no cluster index, the number of I/O operations is cut in half.
- When should you use a hash cluster? A cluster contains all the data for a specific value of the cluster key in a limited number of data blocks. You may have data that is appropriate for a cluster, but whose cluster key has an unequal distribution of values. This would result in the data for some key values being much larger than others, which would in turn force you to size the cluster to accommodate the largest sets of rows, which would waste space for the smaller sets of rows. In this case, you might use a hash cluster to force a more even distribution of rows and still get the advantages of a cluster. The next lesson explores how to create and size a hash cluster.