| Lesson 3 | Creating Oracle cluster |
| Objective | Deciding which table or tables to cluster |
Deciding which Tables to Cluster
The most important step in creating a cluster is deciding which table or tables to cluster, and how. Although a clustered table can deliver a terrific performance improvement in the right circumstances, a poorly chosen cluster can decrease performance. Once you have properly selected the table or tables you wish to cluster, you must go through a three-step process to create this database structure.
Create Hash Cluster
The following Tooltip illustrates how to create a cluster using SQL: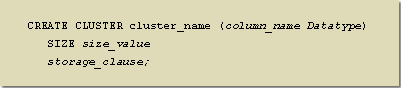
- Required keywords.
- The unique name for the cluster.
- The name of the column or columns that will make up the cluster key. These names are unique to the cluster, but they do not have to match the names of the corresponding columns in the clustered tables
- One of the standard Oracle column datatypes, except for LONG RAW and RAW. Although the names of the columns in the clustered table do not have to match the -column_name, the datatypes of the corresponding columns do have to match.
- A required keyword.
- The size of the cluster needed to store all the rows with the same value for the cluster key. Sizing a cluster is discussed in more detail in the next lesson.
- Contains the same types of storage options as the storage clause for a table, such as TABLESPACE and PCTFREE
CREATE CLUSTER cluster_name (column_name Datatype) SIZE size_value storage_clause;
Oracle Cluster Advantages
Add tables to the cluster
Once you create a cluster, you then create the table or tables that the cluster will contain.
The syntax for creating tables that are a part of a cluster is exactly the same syntax that is used for non-clustered tables, with one exception. The final clause in the CREATE TABLE statement is:
The syntax for creating tables that are a part of a cluster is exactly the same syntax that is used for non-clustered tables, with one exception. The final clause in the CREATE TABLE statement is:
CLUSTER cluster_name (column_name)
The cluster_name is the same name that was given to the cluster in the CREATE CLUSTER command.
The column_name is a list of columns in the table being created that match up with the columns in the already created cluster.
Create the cluster key
The final step is to create a cluster index. You will learn to do this in Lesson 5 of this module.
Cluster Example
The following simplified code is an example of creating a cluster and the tables it will contain:
CREATE CLUSTER orders (order_id NUMBER) SIZE 512 K; CREATE TABLE order_header( order_number NUMBER, customer_number NUMBER) CLUSTER orders (order_number); CREATE TABLE order_detail( order_number NUMBER, detail_line VARCHAR2(100)) CLUSTER orders (order_number);
The next lesson explains how to size a cluster properly.