The order of the table names in the FROM clause determines the driving table for the rule-based query. It is very important to place the table that will return the smallest number of rows last in our FROM clause.
The Driving Table
To review, rows from the driving table are retrieved first, and rows from the other table are then probed for corresponding values.
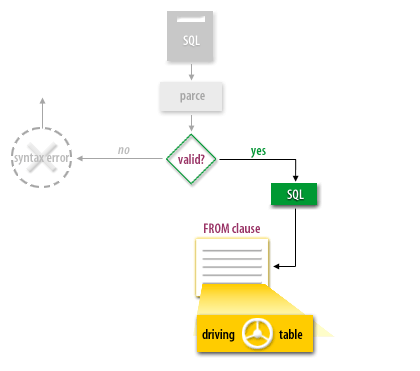
The flowchart you've provided visually represents the execution flow of an SQL statement with a focus on how the driving table is determined, particularly in the context of Rule-Based Optimization (RBO) or Cost-Based Optimization with hints like `ORDERED`.
🔍 Logic Intent Extracted from the Diagram
SQL Statement Submission:
An SQL query is submitted for processing.
Parsing Phase:
The SQL statement is parsed to verify structure and syntax.
Validation Check:
The statement is checked for syntax errors:
❌ If not valid, execution halts and a syntax error is returned.
✅ If valid, proceed to the next step.
FROM Clause Analysis:
The SQL engine reads the FROM clause to determine join order.
The first table listed in the FROM clause is selected as the driving table (especially in RBO or when using the ORDERED hint in CBO).
Driving Table Access:
Oracle retrieves rows from the driving table first.
For each row in the driving table, Oracle probes the other tables for matching rows (typically using nested loops or other join methods).
💡 Key Optimization Insight
The driving table serves as the anchor point in join operations.
Selecting a selective driving table (i.e., one that reduces the number of rows early) can improve query performance.
This concept was critical in RBO and can still be influenced in CBO with hints like:
SELECT /*+ ORDERED */ ...
✅ Summary
Component
Purpose
SQL
SQL statement submitted for execution
parse
Checks for syntax and structure
valid?
Decision point: valid SQL or error
FROM clause
Read in order to choose driving table
driving table
First table accessed in join process
> This flowchart is a great educational visual to illustrate how query planning begins after parsing, and how table order in the `FROM` clause can dictate execution behavior, especially in historical optimization contexts.
Therefore, it is essential that the second table return the least amount of rows based on the WHERE clause. The driving table is
the table that will return the smallest number of rows, based on the filters in the WHERE clause. This is not always the table
with the smallest number of rows.
Distributed Oracle database Example
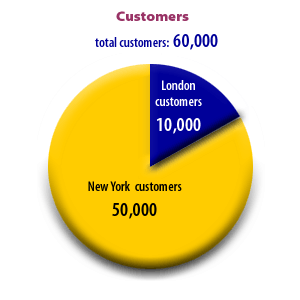
For example, let’s assume that we have a distributed Oracle database with customer tables on several locations. One customer
table resides in London and another in New York, and the distribution of data is shown below.
London distribution
New York distribution
The problem is that the data is skewed. We have the vast majority of customers in New York, so the London table should be last for
unqualified queries. For an unqualified query against these tables, we should specify the New York table first, since London has
the least amount of returned rows:
SELECT
Customer_name
FROM
customer@new_york,
customer@london
;
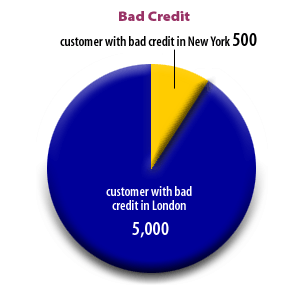
Query for Bad Credit
However, if we query for bad credit, we should put the New York table last, since New York has far fewer deadbeats than London.
SELECT
Customer_name
FROM
customer@london,
customer@new_york
WHERE
Credit_status = ‘BAD’
;
Changing the order of table names in the FROM clause can have a dramatic impact on the performance of nested loop joins[1] . It is common to double the performance of a rule-based query with this technique. Now, let us look at how the order of Boolean operators can also affect the performance in the WHERE clause.
In Oracle Rule-Based Optimization (RBO), the positioning of tables in the `FROM` clause was indeed significant and directly influenced the execution plan. But this concept extends, with some nuances, to other areas of Oracle as well, particularly for Cost-Based Optimization (CBO) and SQL readability/maintenance. Let’s break it down:
In Rule-Based Optimization (RBO):
Yes, positioning mattered.
The RBO followed a fixed heuristic: the order of tables in the FROM clause influenced the join order.
Oracle would choose the first table in the FROM clause as the driving table, assuming no indexes or other access path hints dictated otherwise.
Example:
SELECT * FROM employees e, departments d
WHERE e.department_id = d.department_id;
Here, employees is the driving table.
Important: RBO was deprecated in Oracle 10g and completely removed in Oracle 12c.
In Cost-Based Optimization (CBO):
No, positioning does not directly affect join order—the optimizer uses statistics (table cardinality, selectivity, available indexes, etc.) to determine the best path.
However, you can use optimizer hints (like ORDERED, LEADING, or USE_NL) to force a specific join order or method.
Example using a hint:
SELECT /*+ ORDERED */ *
FROM employees e, departments d
WHERE e.department_id = d.department_id;
This forces the optimizer to treat the FROM clause order as join order.
Other Uses and Areas Where FROM Clause Order Matters:
Query Readability and Maintainability:
Keeping tables in a logical order (e.g., parent to child or dimension to fact) improves code readability, especially in large queries.
View Definitions and Query Transformation:
In materialized views, inline views, or views with complex joins, FROM clause order can impact how the view is rewritten or optimized, especially with query rewrite features.
SQL Baselines and Plans:
When creating SQL Plan Baselines, the original SQL text (including FROM clause order) is part of the match criteria unless normalized.
Join Elimination or Subquery Unnesting:
In certain transformations, Oracle may rewrite subqueries as joins or eliminate joins based on FROM clause relationships.
✅ Summary Table:
Area
Does FROM Clause Order Matter?
Notes
Rule-Based Optimization
✅ Yes
Driving table chosen from left-to-right
Cost-Based Optimization
❌ No (by default)
But hints like `ORDERED` can override
SQL Readability
✅ Yes (for humans)
Logical ordering improves understanding
View Optimization
⚠️ Sometimes
Depends on transformation rules
SQL Plan Baselines
⚠️ Indirectly
Original SQL text matters
Query Rewrite/Transformation
⚠️ Depends
May affect outcome of optimization
If you're tuning SQL under Oracle 19c or 23c using the CBO, focus on statistics, hints, and access paths, rather than relying on `FROM` clause positioning alone.
However, understanding the historical behavior in RBO is still valuable for reading legacy code or understanding optimizer hints.