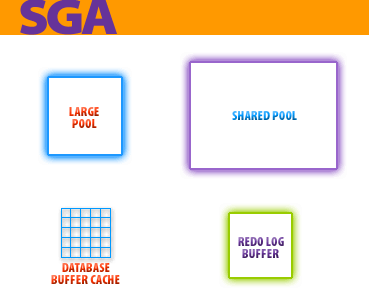
The Oracle instance contains several memory structures located in the
System Global Area, or SGA. Memory structures are contained in the SGA and are shared by user and system processes. The SGA contains both data and control information for an instance, and is referenced by virtually all of the background processes. The benefit of this shared memory model is that information is shared efficiently between the various system processes. The major components of the SGA are shown in the diagram below.
Large Pool: An optional memory area used to store IO buffers for use by Recovery Manager.
Database buffer cache: Holds data blocks that have been read from datafiles.
Redo log buffer: Holds redo log records before they are written to the log files.
Shared pool: Contains parsed versions of SQL statements and other information.
One of the more important changes to the Oracle instance memory structures is the addition of the Large Pool.
The Large Pool
Introduced in Oracle 8, the "Large Pool" helps buffer I/O. It also stores session information if you are using the XA protocol[1].
Both Archive and Recovery Manager benefit greatly from the use of the Large Pool. As with most good features of Oracle, you must tell
the instance that you want to have a Large Pool by setting the LARGE_POOL_SIZEparameter in your init.ora file. If you do not use the Large Pool, Oracle will allocate shared memory buffers from the Shared Pool. Below are the INIT.ORA parameters related to the Large Pool.
The"Large Pool" helps buffer I/O and store session information
The relationship between Oracle's Large Pool, I/O buffering, and the XA protocol.
1. Large Pool and I/O Buffering
Rhe Large Pool can help buffer I/O. It's designed to hold large memory allocations for operations like:
RMAN backup and recovery: When you back up or restore your database, large chunks of data are read and written. The Large Pool can significantly speed this up.
Parallel query: Large sorts, hash joins, and other parallel execution operations can utilize the Large Pool for temporary storage, reducing I/O to disk.
Shared server: In a shared server configuration, session data (UGA) can be stored in the Large Pool.
2. Large Pool and XA Protocol
The Large Pool stores session information when using the XA protocol.
The XA protocol is critical for distributed transactions, where a single transaction spans multiple databases. Here's why the Large Pool is important:
Transaction Context: Each XA transaction needs to maintain context information. This context includes things like the transaction ID, the list of participating resources (databases), and the current state of the transaction.
Large Pool Allocation: This transaction context is stored in the User Global Area (UGA) for each session involved in the XA transaction. In shared server mode or when using the XA protocol, the UGA is allocated from the Large Pool.
Key Takeaways
The Large Pool is a valuable resource for improving performance in various scenarios involving large memory requirements.
For XA transactions, the Large Pool is essential for storing session information and ensuring the integrity of distributed transactions.
Important Notes:
For the following list of 2 elements, put the elements in a HTML unordered list .
Shared Server vs. Dedicated Server: The use of the Large Pool for session information is more relevant in shared server configurations. In dedicated server mode, session information (UGA) is typically stored in the Program Global Area (PGA), which is private to each process.
Configuration: To utilize the Large Pool, you need to explicitly configure it when setting up your Oracle instance. Its size should be based on your specific needs and workload.
If you are working with distributed transactions and the XA protocol, ensure your Large Pool is adequately sized to avoid performance bottlenecks.
Data Files and tablespaces in Oracle
A database is a collection of files stored on disk. The primary component of the database is a tablespace which is a logical unit made up of one
or more physical files on disk or disks.
Data files make up tablespaces in Oracle. Here's how it works:
Tablespaces: These are the logical storage units within an Oracle database. Think of them as containers that hold various database objects like tables, indexes, and other schema objects.
Data files: These are the physical files on your operating system that actually store the data. Each tablespace is comprised of one or more data files.
In essence:
A tablespace is a logical construct.
A data file is a physical file on disk.
Multiple data files can belong to a single tablespace.
A single data file can only belong to one tablespace.
Why this is done:
Flexibility: You can manage your storage by allocating different data files to different storage devices (disks) based on performance needs.
Scalability: You can easily add more space to a tablespace by adding more data files.
Manageability: This separation allows for easier backup and recovery operations at the tablespace level.
There is one tablespace that deserves mention here, the SYSTEM tablespace. This tablespace must be available all the time for the normal operation of your database.
This tablespace contains several unique components, one of which is the data dictionary. The data dictionary contains information about the database and is relatively consistent in size, never really growing compared to the potential growth of user data. A DBA will limit access to the SYSTEM tablespace and will check to make sure that it normally contains 50% free space.
During this course we will refer to various tables and views for the information specific to our installation. For instance, there is a V$SGA view which
will provide the size of the shared pool, log buffer, data buffer cache, and fixed memory sizes. The V$INSTANCE view will return
information about your instance such as name, startup time, and host name.
Managing Data Files and Tablespaces in Oracle 23c
Oracle 23c introduces enhancements to both data file and tablespace management. Below is a detailed description of managing these components:
1. Managing Data Files Data files in Oracle are physical files that store the data for tablespaces. Oracle 23c offers robust features for data file management.
Key Features
Automatic File Management (AFM): Oracle 23c automates the allocation and extension of data files using the Oracle Managed Files (OMF) feature.
Support for Larger Files: Oracle 23c supports very large data files to accommodate modern data growth, including hybrid environments with on-premises and cloud deployments.
Transparent Encryption: Oracle Advanced Security can encrypt data files to ensure compliance with security standards.
Tasks in Managing Data Files
Adding Data Files
Data files can be added manually or automatically when a tablespace grows. Use the following command to add a data file:
ALTER DATABASE DATAFILE '/u01/oracle/datafile1.dbf' ADD SIZE 50M;
With OMF enabled:
ALTER DATABASE ADD DATAFILE AUTOEXTEND ON NEXT 10M MAXSIZE UNLIMITED;
Resizing Data Files
You can manually resize data files to manage disk space:
ALTER DATABASE DATAFILE '/u01/oracle/datafile1.dbf' RESIZE 100M;
Autoextending Data Files
Enable auto-extension to allow the file to grow automatically:
ALTER DATABASE DATAFILE '/u01/oracle/datafile1.dbf' AUTOEXTEND ON NEXT 10M MAXSIZE 500M;
Dropping Data Files
Dropping data files directly is not supported. You must drop the tablespace that contains the data file.
Monitoring Data Files
Use the DBA_DATA_FILES view to monitor data file usage:
SELECT FILE_NAME, TABLESPACE_NAME, BYTES, AUTOEXTENSIBLE FROM DBA_DATA_FILES;
2. Managing Tablespaces: Tablespaces are logical storage units that organize and group related database objects. Oracle 23c offers advanced tablespace management capabilities.
Key Features
Read-Only Tablespaces: Optimize performance by marking tablespaces as read-only.
Temporary Tablespaces: Improved support for managing temporary tablespaces for sort operations.
Bigfile Tablespaces: Allow single data files up to 8 exabytes, simplifying management of large datasets.
Undo Tablespaces Enhancements: Improved performance and visibility for undo management.
Types of Tablespaces
SYSTEM and SYSAUX: Required tablespaces for Oracle database operation.
PERMANENT: Stores user data and indexes.
TEMPORARY: Used for temporary operations like sorting.
UNDO: Manages undo data for transactions.
Tasks in Managing Tablespaces
Creating Tablespaces
Create a new tablespace:
CREATE TABLESPACE users
DATAFILE '/u01/oracle/users01.dbf' SIZE 50M AUTOEXTEND ON NEXT 10M MAXSIZE 500M;
Create a Bigfile Tablespace:
CREATE BIGFILE TABLESPACE big_users
DATAFILE '/u01/oracle/big_users01.dbf' SIZE 10G AUTOEXTEND ON NEXT 1G MAXSIZE UNLIMITED;
Altering Tablespaces
Add data files:
ALTER TABLESPACE users ADD DATAFILE '/u01/oracle/users02.dbf' SIZE 50M AUTOEXTEND ON;
Change tablespace status to READ ONLY:
ALTER TABLESPACE users READ ONLY;
Dropping Tablespaces
Drop a tablespace along with its data files:
DROP TABLESPACE users INCLUDING CONTENTS AND DATAFILES;
Monitoring Tablespaces
Use the DBA_TABLESPACES view:
SELECT TABLESPACE_NAME, STATUS, CONTENTS, BIGFILE FROM DBA_TABLESPACES;
Temporary Tablespace Management
Create a temporary tablespace:
CREATE TEMPORARY TABLESPACE temp1
TEMPFILE '/u01/oracle/temp01.dbf' SIZE 50M AUTOEXTEND ON NEXT 10M MAXSIZE UNLIMITED;
Assign a default temporary tablespace to users:
ALTER DATABASE DEFAULT TEMPORARY TABLESPACE temp1;
Heat Maps: Tablespaces can use heat maps to identify frequently accessed blocks, optimizing storage placement.
Automatic Data Optimization (ADO): Oracle 23c supports automating the movement of data between storage tiers based on usage.
Tablespace Cloning: Allows quick cloning of tablespaces for test or backup purposes.
Hybrid Partitioned Tablespaces: Supports hybrid environments by combining local and cloud storage.
By understanding and implementing these features, Oracle 23c users can efficiently manage storage and optimize performance.
select FROM v$instance;
The queries below are valid for both Oracle 11g and Oracle 19c, as the `V$INSTANCE` view is available and has not significantly changed between these versions. However, there are slight differences in output, such as potential additional columns or features in newer Oracle versions like 19c.
Here’s how you can adapt or enhance the query for each version:
Oracle 11g: For Oracle 11g, no changes are required. The query will work as is:
SELECT instance_number, instance_name, version, status
FROM v$instance;
Output will display `instance_number`, `instance_name`, `version`, and `status`, which are standard columns in Oracle 11g.
Oracle 19c: In Oracle 19c, while the query remains valid, you might want to include additional information about the database to reflect modern features or configurations, such as checking `DB_UNIQUE_NAME` or `BLOCKED` status. For example:
SELECT instance_number, instance_name, version, status, db_unique_name, blocked
FROM v$instance;
DB_UNIQUE_NAME: Useful in a multitenant or distributed database environment.
BLOCKED: Indicates whether the instance is blocked for updates (e.g., due to patching or certain failover scenarios).
Notes
If the DB_UNIQUE_NAME or BLOCKED columns are unnecessary, the original query will still work seamlessly in both Oracle 11g and Oracle 19c.
For better compatibility, you may include a version check to ensure that additional columns do not cause errors in older versions.
The next lesson explores Oracle background processes.
[1]XA Protocol: XA Protocol is a standard that defines how a database, like an Oracle instance, participates in distributed transactions managed by an external transaction manager. This ensures data integrity across multiple resources, even if they reside in different databases or systems. Within the Oracle instance memory, XA Protocol interacts with the System Global Area (SGA), specifically the shared pool and buffer cache, to manage transaction states and data consistency during the two-phase commit process.